Introduction
----
This document is a tutorial introduction to the basics of the Go programming
language, intended for programmers familiar with C or C++. It is not a comprehensive
guide to the language; at the moment the document closest to that is the
language specification.
After you've read this tutorial, you might want to look at
Effective Go,
which digs deeper into how the language is used.
Also, slides from a 3-day course about Go are available:
Day 1,
Day 2,
Day 3.
The presentation here proceeds through a series of modest programs to illustrate
key features of the language. All the programs work (at time of writing) and are
checked into the repository in the directory "/doc/progs/".
Program snippets are annotated with the line number in the original file; for
cleanliness, blank lines remain blank.
Hello, World
----
Let's start in the usual way:
--PROG progs/helloworld.go /package/ END
Every Go source file declares, using a "package" statement, which package it's part of.
It may also import other packages to use their facilities.
This program imports the package "fmt" to gain access to
our old, now capitalized and package-qualified, friend, "fmt.Printf".
Functions are introduced with the "func" keyword.
The "main" package's "main" function is where the program starts running (after
any initialization).
String constants can contain Unicode characters, encoded in UTF-8.
(In fact, Go source files are defined to be encoded in UTF-8.)
The comment convention is the same as in C++:
/* ... */
// ...
Later we'll have much more to say about printing.
Semicolons
----
You might have noticed that our program has no semicolons. In Go
code, the only place you typically see semicolons is separating the
clauses of "for" loops and the like; they are not necessary after
every statement.
In fact, what happens is that the formal language uses semicolons,
much as in C or Java, but they are inserted automatically
at the end of every line that looks like the end of a statement. You
don't need to type them yourself.
For details about how this is done you can see the language
specification, but in practice all you need to know is that you
never need to put a semicolon at the end of a line. (You can put
them in if you want to write multiple statements per line.) As an
extra help, you can also leave out a semicolon immediately before
a closing brace.
This approach makes for clean-looking, semicolon-free code. The
one surprise is that it's important to put the opening
brace of a construct such as an "if" statement on the same line as
the "if"; if you don't, there are situations that may not compile
or may give the wrong result. The language forces the brace style
to some extent.
Compiling
----
Go is a compiled language. At the moment there are two compilers.
"Gccgo" is a Go compiler that uses the GCC back end. There is also a
suite of compilers with different (and odd) names for each architecture:
"6g" for the 64-bit x86, "8g" for the 32-bit x86, and more. These
compilers run significantly faster but generate less efficient code
than "gccgo". At the time of writing (late 2009), they also have
a more robust run-time system although "gccgo" is catching up.
Here's how to compile and run our program. With "6g", say,
$ 6g helloworld.go # compile; object goes into helloworld.6
$ 6l helloworld.6 # link; output goes into 6.out
$ 6.out
Hello, world; or Καλημέρα κόσμε; or こんにちは 世界
$
With "gccgo" it looks a little more traditional.
$ gccgo helloworld.go
$ a.out
Hello, world; or Καλημέρα κόσμε; or こんにちは 世界
$
Echo
----
Next up, here's a version of the Unix utility "echo(1)":
--PROG progs/echo.go /package/ END
This program is small but it's doing a number of new things. In the last example,
we saw "func" introduce a function. The keywords "var", "const", and "type"
(not used yet) also introduce declarations, as does "import".
Notice that we can group declarations of the same sort into
parenthesized lists, one item per line, as on lines 7-10 and 14-17.
But it's not necessary to do so; we could have said
const Space = " "
const Newline = "\n"
This program imports the ""os"" package to access its "Stdout" variable, of type
"*os.File". The "import" statement is actually a declaration: in its general form,
as used in our ``hello world'' program,
it names the identifier ("fmt")
that will be used to access members of the package imported from the file (""fmt""),
found in the current directory or in a standard location.
In this program, though, we've dropped the explicit name from the imports; by default,
packages are imported using the name defined by the imported package,
which by convention is of course the file name itself. Our ``hello world'' program
could have said just "import "fmt"".
You can specify your
own import names if you want but it's only necessary if you need to resolve
a naming conflict.
Given "os.Stdout" we can use its "WriteString" method to print the string.
Having imported the "flag" package, line 12 creates a global variable to hold
the value of echo's "-n" flag. The variable "omitNewline" has type "*bool", pointer
to "bool".
In "main.main", we parse the arguments (line 20) and then create a local
string variable we will use to build the output.
The declaration statement has the form
var s string = ""
This is the "var" keyword, followed by the name of the variable, followed by
its type, followed by an equals sign and an initial value for the variable.
Go tries to be terse, and this declaration could be shortened. Since the
string constant is of type string, we don't have to tell the compiler that.
We could write
var s = ""
or we could go even shorter and write the idiom
s := ""
The ":=" operator is used a lot in Go to represent an initializing declaration.
There's one in the "for" clause on the next line:
--PROG progs/echo.go /for/
The "flag" package has parsed the arguments and left the non-flag arguments
in a list that can be iterated over in the obvious way.
The Go "for" statement differs from that of C in a number of ways. First,
it's the only looping construct; there is no "while" or "do". Second,
there are no parentheses on the clause, but the braces on the body
are mandatory. The same applies to the "if" and "switch" statements.
Later examples will show some other ways "for" can be written.
The body of the loop builds up the string "s" by appending (using "+=")
the arguments and separating spaces. After the loop, if the "-n" flag is not
set, the program appends a newline. Finally, it writes the result.
Notice that "main.main" is a niladic function with no return type.
It's defined that way. Falling off the end of "main.main" means
''success''; if you want to signal an erroneous return, call
os.Exit(1)
The "os" package contains other essentials for getting
started; for instance, "os.Args" is a slice used by the
"flag" package to access the command-line arguments.
An Interlude about Types
----
Go has some familiar types such as "int" and "float", which represent
values of the ''appropriate'' size for the machine. It also defines
explicitly-sized types such as "int8", "float64", and so on, plus
unsigned integer types such as "uint", "uint32", etc. These are
distinct types; even if "int" and "int32" are both 32 bits in size,
they are not the same type. There is also a "byte" synonym for
"uint8", which is the element type for strings.
Speaking of "string", that's a built-in type as well. Strings are
immutable values—they are not just arrays of "byte" values.
Once you've built a string value, you can't change it, although
of course you can change a string variable simply by
reassigning it. This snippet from "strings.go" is legal code:
--PROG progs/strings.go /hello/ /ciao/
However the following statements are illegal because they would modify
a "string" value:
s[0] = 'x'
(*p)[1] = 'y'
In C++ terms, Go strings are a bit like "const strings", while pointers
to strings are analogous to "const string" references.
Yes, there are pointers. However, Go simplifies their use a little;
read on.
Arrays are declared like this:
var arrayOfInt [10]int
Arrays, like strings, are values, but they are mutable. This differs
from C, in which "arrayOfInt" would be usable as a pointer to "int".
In Go, since arrays are values, it's meaningful (and useful) to talk
about pointers to arrays.
The size of the array is part of its type; however, one can declare
a slice variable to hold a reference to any array, of any size,
with the same element type.
A slice
expression has the form "a[low : high]", representing
the internal array indexed from "low" through "high-1"; the resulting
slice is indexed from "0" through "high-low-1".
In short, slices look a lot like arrays but with
no explicit size ("[]" vs. "[10]") and they reference a segment of
an underlying, usually anonymous, regular array. Multiple slices
can share data if they represent pieces of the same array;
multiple arrays can never share data.
Slices are much more common in Go programs than
regular arrays; they're more flexible, have reference semantics,
and are efficient. What they lack is the precise control of storage
layout of a regular array; if you want to have a hundred elements
of an array stored within your structure, you should use a regular
array. To create one, use a compound value constructor—an
expression formed
from a type followed by a brace-bounded expression like this:
[3]int{1,2,3}
In this case the constructor builds an array of 3 "ints".
When passing an array to a function, you almost always want
to declare the formal parameter to be a slice. When you call
the function, slice the array to create
(efficiently) a slice reference and pass that.
By default, the lower and upper bounds of a slice match the
ends of the existing object, so the concise notation "[:]"
will slice the whole array.
Using slices one can write this function (from "sum.go"):
--PROG progs/sum.go /sum/ /^}/
Note how the return type ("int") is defined for "sum()" by stating it
after the parameter list.
To call the function, we slice the array. This intricate call (we'll show
a simpler way in a moment) constructs
an array and slices it:
s := sum([3]int{1,2,3}[:])
If you are creating a regular array but want the compiler to count the
elements for you, use "..." as the array size:
s := sum([...]int{1,2,3}[:])
That's fussier than necessary, though.
In practice, unless you're meticulous about storage layout within a
data structure, a slice itself—using empty brackets with no size—is all you need:
s := sum([]int{1,2,3})
There are also maps, which you can initialize like this:
m := map[string]int{"one":1 , "two":2}
The built-in function "len()", which returns number of elements,
makes its first appearance in "sum". It works on strings, arrays,
slices, maps, and channels.
By the way, another thing that works on strings, arrays, slices, maps
and channels is the "range" clause on "for" loops. Instead of writing
for i := 0; i < len(a); i++ { ... }
to loop over the elements of a slice (or map or ...) , we could write
for i, v := range a { ... }
This assigns "i" to the index and "v" to the value of the successive
elements of the target of the range. See
Effective Go
for more examples of its use.
An Interlude about Allocation
----
Most types in Go are values. If you have an "int" or a "struct"
or an array, assignment
copies the contents of the object.
To allocate a new variable, use "new()", which
returns a pointer to the allocated storage.
type T struct { a, b int }
var t *T = new(T)
or the more idiomatic
t := new(T)
Some types—maps, slices, and channels (see below)—have reference semantics.
If you're holding a slice or a map and you modify its contents, other variables
referencing the same underlying data will see the modification. For these three
types you want to use the built-in function "make()":
m := make(map[string]int)
This statement initializes a new map ready to store entries.
If you just declare the map, as in
var m map[string]int
it creates a "nil" reference that cannot hold anything. To use the map,
you must first initialize the reference using "make()" or by assignment from an
existing map.
Note that "new(T)" returns type "*T" while "make(T)" returns type
"T". If you (mistakenly) allocate a reference object with "new()",
you receive a pointer to a nil reference, equivalent to
declaring an uninitialized variable and taking its address.
An Interlude about Constants
----
Although integers come in lots of sizes in Go, integer constants do not.
There are no constants like "0LL" or "0x0UL". Instead, integer
constants are evaluated as large-precision values that
can overflow only when they are assigned to an integer variable with
too little precision to represent the value.
const hardEight = (1 << 100) >> 97 // legal
There are nuances that deserve redirection to the legalese of the
language specification but here are some illustrative examples:
var a uint64 = 0 // a has type uint64, value 0
a := uint64(0) // equivalent; uses a "conversion"
i := 0x1234 // i gets default type: int
var j int = 1e6 // legal - 1000000 is representable in an int
x := 1.5 // a float
i3div2 := 3/2 // integer division - result is 1
f3div2 := 3./2. // floating point division - result is 1.5
Conversions only work for simple cases such as converting "ints" of one
sign or size to another, and between "ints" and "floats", plus a few other
simple cases. There are no automatic numeric conversions of any kind in Go,
other than that of making constants have concrete size and type when
assigned to a variable.
An I/O Package
----
Next we'll look at a simple package for doing file I/O with the usual
sort of open/close/read/write interface. Here's the start of "file.go":
--PROG progs/file.go /package/ /^}/
The first few lines declare the name of the
package—"file"—and then import two packages. The "os"
package hides the differences
between various operating systems to give a consistent view of files and
so on; here we're going to use its error handling utilities
and reproduce the rudiments of its file I/O.
The other item is the low-level, external "syscall" package, which provides
a primitive interface to the underlying operating system's calls.
Next is a type definition: the "type" keyword introduces a type declaration,
in this case a data structure called "File".
To make things a little more interesting, our "File" includes the name of the file
that the file descriptor refers to.
Because "File" starts with a capital letter, the type is available outside the package,
that is, by users of the package. In Go the rule about visibility of information is
simple: if a name (of a top-level type, function, method, constant or variable, or of
a structure field or method) is capitalized, users of the package may see it. Otherwise, the
name and hence the thing being named is visible only inside the package in which
it is declared. This is more than a convention; the rule is enforced by the compiler.
In Go, the term for publicly visible names is ''exported''.
In the case of "File", all its fields are lower case and so invisible to users, but we
will soon give it some exported, upper-case methods.
First, though, here is a factory to create a "File":
--PROG progs/file.go /newFile/ /^}/
This returns a pointer to a new "File" structure with the file descriptor and name
filled in. This code uses Go's notion of a ''composite literal'', analogous to
the ones used to build maps and arrays, to construct a new heap-allocated
object. We could write
n := new(File)
n.fd = fd
n.name = name
return n
but for simple structures like "File" it's easier to return the address of a
composite literal, as is done here on line 21.
We can use the factory to construct some familiar, exported variables of type "*File":
--PROG progs/file.go /var/ /^.$/
The "newFile" function was not exported because it's internal. The proper,
exported factory to use is "Open":
--PROG progs/file.go /func.Open/ /^}/
There are a number of new things in these few lines. First, "Open" returns
multiple values, a "File" and an error (more about errors in a moment).
We declare the
multi-value return as a parenthesized list of declarations; syntactically
they look just like a second parameter list. The function
"syscall.Open"
also has a multi-value return, which we can grab with the multi-variable
declaration on line 31; it declares "r" and "e" to hold the two values,
both of type "int" (although you'd have to look at the "syscall" package
to see that). Finally, line 35 returns two values: a pointer to the new "File"
and the error. If "syscall.Open" fails, the file descriptor "r" will
be negative and "newFile" will return "nil".
About those errors: The "os" library includes a general notion of an error.
It's a good idea to use its facility in your own interfaces, as we do here, for
consistent error handling throughout Go code. In "Open" we use a
conversion to translate Unix's integer "errno" value into the integer type
"os.Errno", which implements "os.Error".
Now that we can build "Files", we can write methods for them. To declare
a method of a type, we define a function to have an explicit receiver
of that type, placed
in parentheses before the function name. Here are some methods for "*File",
each of which declares a receiver variable "file".
--PROG progs/file.go /Close/ END
There is no implicit "this" and the receiver variable must be used to access
members of the structure. Methods are not declared within
the "struct" declaration itself. The "struct" declaration defines only data members.
In fact, methods can be created for almost any type you name, such as an integer or
array, not just for "structs". We'll see an example with arrays later.
The "String" method is so called because of a printing convention we'll
describe later.
The methods use the public variable "os.EINVAL" to return the ("os.Error"
version of the) Unix error code "EINVAL". The "os" library defines a standard
set of such error values.
We can now use our new package:
--PROG progs/helloworld3.go /package/ END
The ''"./"'' in the import of ''"./file"'' tells the compiler
to use our own package rather than
something from the directory of installed packages.
(Also, ''"file.go"'' must be compiled before we can import the
package.)
Now we can compile and run the program. On Unix, this would be the result:
$ 6g file.go # compile file package
$ 6g helloworld3.go # compile main package
$ 6l -o helloworld3 helloworld3.6 # link - no need to mention "file"
$ helloworld3
hello, world
can't open file; err=No such file or directory
$
Rotting cats
----
Building on the "file" package, here's a simple version of the Unix utility "cat(1)",
"progs/cat.go":
--PROG progs/cat.go /package/ END
By now this should be easy to follow, but the "switch" statement introduces some
new features. Like a "for" loop, an "if" or "switch" can include an
initialization statement. The "switch" on line 18 uses one to create variables
"nr" and "er" to hold the return values from "f.Read()". (The "if" on line 25
has the same idea.) The "switch" statement is general: it evaluates the cases
from top to bottom looking for the first case that matches the value; the
case expressions don't need to be constants or even integers, as long as
they all have the same type.
Since the "switch" value is just "true", we could leave it off—as is also
the situation
in a "for" statement, a missing value means "true". In fact, such a "switch"
is a form of "if-else" chain. While we're here, it should be mentioned that in
"switch" statements each "case" has an implicit "break".
Line 25 calls "Write()" by slicing the incoming buffer, which is itself a slice.
Slices provide the standard Go way to handle I/O buffers.
Now let's make a variant of "cat" that optionally does "rot13" on its input.
It's easy to do by just processing the bytes, but instead we will exploit
Go's notion of an interface.
The "cat()" subroutine uses only two methods of "f": "Read()" and "String()",
so let's start by defining an interface that has exactly those two methods.
Here is code from "progs/cat_rot13.go":
--PROG progs/cat_rot13.go /type.reader/ /^}/
Any type that has the two methods of "reader"—regardless of whatever
other methods the type may also have—is said to implement the
interface. Since "file.File" implements these methods, it implements the
"reader" interface. We could tweak the "cat" subroutine to accept a "reader"
instead of a "*file.File" and it would work just fine, but let's embellish a little
first by writing a second type that implements "reader", one that wraps an
existing "reader" and does "rot13" on the data. To do this, we just define
the type and implement the methods and with no other bookkeeping,
we have a second implementation of the "reader" interface.
--PROG progs/cat_rot13.go /type.rotate13/ /end.of.rotate13/
(The "rot13" function called on line 42 is trivial and not worth reproducing here.)
To use the new feature, we define a flag:
--PROG progs/cat_rot13.go /rot13Flag/
and use it from within a mostly unchanged "cat()" function:
--PROG progs/cat_rot13.go /func.cat/ /^}/
(We could also do the wrapping in "main" and leave "cat()" mostly alone, except
for changing the type of the argument; consider that an exercise.)
Lines 56 through 58 set it all up: If the "rot13" flag is true, wrap the "reader"
we received into a "rotate13" and proceed. Note that the interface variables
are values, not pointers: the argument is of type "reader", not "*reader",
even though under the covers it holds a pointer to a "struct".
Here it is in action:
$ echo abcdefghijklmnopqrstuvwxyz | ./cat
abcdefghijklmnopqrstuvwxyz
$ echo abcdefghijklmnopqrstuvwxyz | ./cat --rot13
nopqrstuvwxyzabcdefghijklm
$
Fans of dependency injection may take cheer from how easily interfaces
allow us to substitute the implementation of a file descriptor.
Interfaces are a distinctive feature of Go. An interface is implemented by a
type if the type implements all the methods declared in the interface.
This means
that a type may implement an arbitrary number of different interfaces.
There is no type hierarchy; things can be much more ad hoc,
as we saw with "rot13". The type "file.File" implements "reader"; it could also
implement a "writer", or any other interface built from its methods that
fits the current situation. Consider the empty interface
type Empty interface {}
Every type implements the empty interface, which makes it
useful for things like containers.
Sorting
----
Interfaces provide a simple form of polymorphism. They completely
separate the definition of what an object does from how it does it, allowing
distinct implementations to be represented at different times by the
same interface variable.
As an example, consider this simple sort algorithm taken from "progs/sort.go":
--PROG progs/sort.go /func.Sort/ /^}/
The code needs only three methods, which we wrap into sort's "Interface":
--PROG progs/sort.go /interface/ /^}/
We can apply "Sort" to any type that implements "Len", "Less", and "Swap".
The "sort" package includes the necessary methods to allow sorting of
arrays of integers, strings, etc.; here's the code for arrays of "int"
--PROG progs/sort.go /type.*IntArray/ /Swap/
Here we see methods defined for non-"struct" types. You can define methods
for any type you define and name in your package.
And now a routine to test it out, from "progs/sortmain.go". This
uses a function in the "sort" package, omitted here for brevity,
to test that the result is sorted.
--PROG progs/sortmain.go /func.ints/ /^}/
If we have a new type we want to be able to sort, all we need to do is
to implement the three methods for that type, like this:
--PROG progs/sortmain.go /type.day/ /Swap/
Printing
----
The examples of formatted printing so far have been modest. In this section
we'll talk about how formatted I/O can be done well in Go.
We've seen simple uses of the package "fmt", which
implements "Printf", "Fprintf", and so on.
Within the "fmt" package, "Printf" is declared with this signature:
Printf(format string, v ...interface{}) (n int, errno os.Error)
The token "..." introduces a variable-length argument list that in C would
be handled using the "stdarg.h" macros.
In Go, variadic functions are passed a slice of the arguments of the
specified type. In "Printf"'s case, the declaration says "...interface{}"
so the actual type is a slice of empty interface values, "[]interface{}".
"Printf" can examine the arguments by iterating over the slice
and, for each element, using a type switch or the reflection library
to interpret the value.
It's off topic here but such run-time type analysis
helps explain some of the nice properties of Go's "Printf",
due to the ability of "Printf" to discover the type of its arguments
dynamically.
For example, in C each format must correspond to the type of its
argument. It's easier in many cases in Go. Instead of "%llud" you
can just say "%d"; "Printf" knows the size and signedness of the
integer and can do the right thing for you. The snippet
--PROG progs/print.go 'NR==10' 'NR==11'
prints
18446744073709551615 -1
In fact, if you're lazy the format "%v" will print, in a simple
appropriate style, any value, even an array or structure. The output of
--PROG progs/print.go 'NR==14' 'NR==20'
is
18446744073709551615 {77 Sunset Strip} [1 2 3 4]
You can drop the formatting altogether if you use "Print" or "Println"
instead of "Printf". Those routines do fully automatic formatting.
The "Print" function just prints its elements out using the equivalent
of "%v" while "Println" inserts spaces between arguments
and adds a newline. The output of each of these two lines is identical
to that of the "Printf" call above.
--PROG progs/print.go 'NR==21' 'NR==22'
If you have your own type you'd like "Printf" or "Print" to format,
just give it a "String()" method that returns a string. The print
routines will examine the value to inquire whether it implements
the method and if so, use it rather than some other formatting.
Here's a simple example.
--PROG progs/print_string.go 'NR==9' END
Since "*testType" has a "String()" method, the
default formatter for that type will use it and produce the output
77 Sunset Strip
Observe that the "String()" method calls "Sprint" (the obvious Go
variant that returns a string) to do its formatting; special formatters
can use the "fmt" library recursively.
Another feature of "Printf" is that the format "%T" will print a string
representation of the type of a value, which can be handy when debugging
polymorphic code.
It's possible to write full custom print formats with flags and precisions
and such, but that's getting a little off the main thread so we'll leave it
as an exploration exercise.
You might ask, though, how "Printf" can tell whether a type implements
the "String()" method. Actually what it does is ask if the value can
be converted to an interface variable that implements the method.
Schematically, given a value "v", it does this:
type Stringer interface {
String() string
}
s, ok := v.(Stringer) // Test whether v implements "String()"
if ok {
result = s.String()
} else {
result = defaultOutput(v)
}
The code uses a ``type assertion'' ("v.(Stringer)") to test if the value stored in
"v" satisfies the "Stringer" interface; if it does, "s"
will become an interface variable implementing the method and "ok" will
be "true". We then use the interface variable to call the method.
(The ''comma, ok'' pattern is a Go idiom used to test the success of
operations such as type conversion, map update, communications, and so on,
although this is the only appearance in this tutorial.)
If the value does not satisfy the interface, "ok" will be false.
In this snippet the name "Stringer" follows the convention that we add ''[e]r''
to interfaces describing simple method sets like this.
One last wrinkle. To complete the suite, besides "Printf" etc. and "Sprintf"
etc., there are also "Fprintf" etc. Unlike in C, "Fprintf"'s first argument is
not a file. Instead, it is a variable of type "io.Writer", which is an
interface type defined in the "io" library:
type Writer interface {
Write(p []byte) (n int, err os.Error)
}
(This interface is another conventional name, this time for "Write"; there are also
"io.Reader", "io.ReadWriter", and so on.)
Thus you can call "Fprintf" on any type that implements a standard "Write()"
method, not just files but also network channels, buffers, whatever
you want.
Prime numbers
----
Now we come to processes and communication—concurrent programming.
It's a big subject so to be brief we assume some familiarity with the topic.
A classic program in the style is a prime sieve.
(The sieve of Eratosthenes is computationally more efficient than
the algorithm presented here, but we are more interested in concurrency than
algorithmics at the moment.)
It works by taking a stream of all the natural numbers and introducing
a sequence of filters, one for each prime, to winnow the multiples of
that prime. At each step we have a sequence of filters of the primes
so far, and the next number to pop out is the next prime, which triggers
the creation of the next filter in the chain.
Here's a flow diagram; each box represents a filter element whose
creation is triggered by the first number that flowed from the
elements before it.
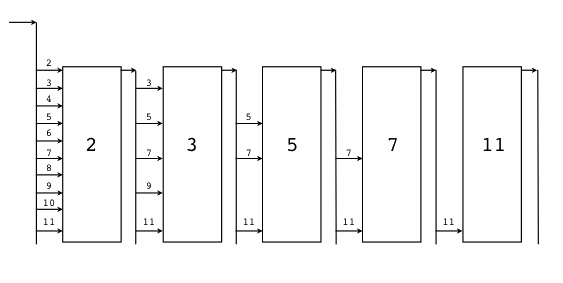
To create a stream of integers, we use a Go channel, which,
borrowing from CSP's descendants, represents a communications
channel that can connect two concurrent computations.
In Go, channel variables are references to a run-time object that
coordinates the communication; as with maps and slices, use
"make" to create a new channel.
Here is the first function in "progs/sieve.go":
--PROG progs/sieve.go /Send/ /^}/
The "generate" function sends the sequence 2, 3, 4, 5, ... to its
argument channel, "ch", using the binary communications operator "<-".
Channel operations block, so if there's no recipient for the value on "ch",
the send operation will wait until one becomes available.
The "filter" function has three arguments: an input channel, an output
channel, and a prime number. It copies values from the input to the
output, discarding anything divisible by the prime. The unary communications
operator "<-" (receive) retrieves the next value on the channel.
--PROG progs/sieve.go /Copy.the/ /^}/
The generator and filters execute concurrently. Go has
its own model of process/threads/light-weight processes/coroutines,
so to avoid notational confusion we call concurrently executing
computations in Go goroutines. To start a goroutine,
invoke the function, prefixing the call with the keyword "go";
this starts the function running in parallel with the current
computation but in the same address space:
go sum(hugeArray) // calculate sum in the background
If you want to know when the calculation is done, pass a channel
on which it can report back:
ch := make(chan int)
go sum(hugeArray, ch)
// ... do something else for a while
result := <-ch // wait for, and retrieve, result
Back to our prime sieve. Here's how the sieve pipeline is stitched
together:
--PROG progs/sieve.go /func.main/ /^}/
Line 29 creates the initial channel to pass to "generate", which it
then starts up. As each prime pops out of the channel, a new "filter"
is added to the pipeline and its output becomes the new value
of "ch".
The sieve program can be tweaked to use a pattern common
in this style of programming. Here is a variant version
of "generate", from "progs/sieve1.go":
--PROG progs/sieve1.go /func.generate/ /^}/
This version does all the setup internally. It creates the output
channel, launches a goroutine running a function literal, and
returns the channel to the caller. It is a factory for concurrent
execution, starting the goroutine and returning its connection.
The function literal notation (lines 12-16) allows us to construct an
anonymous function and invoke it on the spot. Notice that the local
variable "ch" is available to the function literal and lives on even
after "generate" returns.
The same change can be made to "filter":
--PROG progs/sieve1.go /func.filter/ /^}/
The "sieve" function's main loop becomes simpler and clearer as a
result, and while we're at it let's turn it into a factory too:
--PROG progs/sieve1.go /func.sieve/ /^}/
Now "main"'s interface to the prime sieve is a channel of primes:
--PROG progs/sieve1.go /func.main/ /^}/
Multiplexing
----
With channels, it's possible to serve multiple independent client goroutines without
writing an explicit multiplexer. The trick is to send the server a channel in the message,
which it will then use to reply to the original sender.
A realistic client-server program is a lot of code, so here is a very simple substitute
to illustrate the idea. It starts by defining a "request" type, which embeds a channel
that will be used for the reply.
--PROG progs/server.go /type.request/ /^}/
The server will be trivial: it will do simple binary operations on integers. Here's the
code that invokes the operation and responds to the request:
--PROG progs/server.go /type.binOp/ /^}/
Line 14 defines the name "binOp" to be a function taking two integers and
returning a third.
The "server" routine loops forever, receiving requests and, to avoid blocking due to
a long-running operation, starting a goroutine to do the actual work.
--PROG progs/server.go /func.server/ /^}/
We construct a server in a familiar way, starting it and returning a channel
connected to it:
--PROG progs/server.go /func.startServer/ /^}/
Here's a simple test. It starts a server with an addition operator and sends out
"N" requests without waiting for the replies. Only after all the requests are sent
does it check the results.
--PROG progs/server.go /func.main/ /^}/
One annoyance with this program is that it doesn't shut down the server cleanly; when "main" returns
there are a number of lingering goroutines blocked on communication. To solve this,
we can provide a second, "quit" channel to the server:
--PROG progs/server1.go /func.startServer/ /^}/
It passes the quit channel to the "server" function, which uses it like this:
--PROG progs/server1.go /func.server/ /^}/
Inside "server", the "select" statement chooses which of the multiple communications
listed by its cases can proceed. If all are blocked, it waits until one can proceed; if
multiple can proceed, it chooses one at random. In this instance, the "select" allows
the server to honor requests until it receives a quit message, at which point it
returns, terminating its execution.
All that's left is to strobe the "quit" channel
at the end of main:
--PROG progs/server1.go /adder,.quit/
...
--PROG progs/server1.go /quit....true/
There's a lot more to Go programming and concurrent programming in general but this
quick tour should give you some of the basics.